Package Structure
structure.RmdStructure
This is an overall structure of the samrat package,
which details how the different analysis elements (parameters, analysis,
plotting etc) are functionally related.
The package structure is shown below:
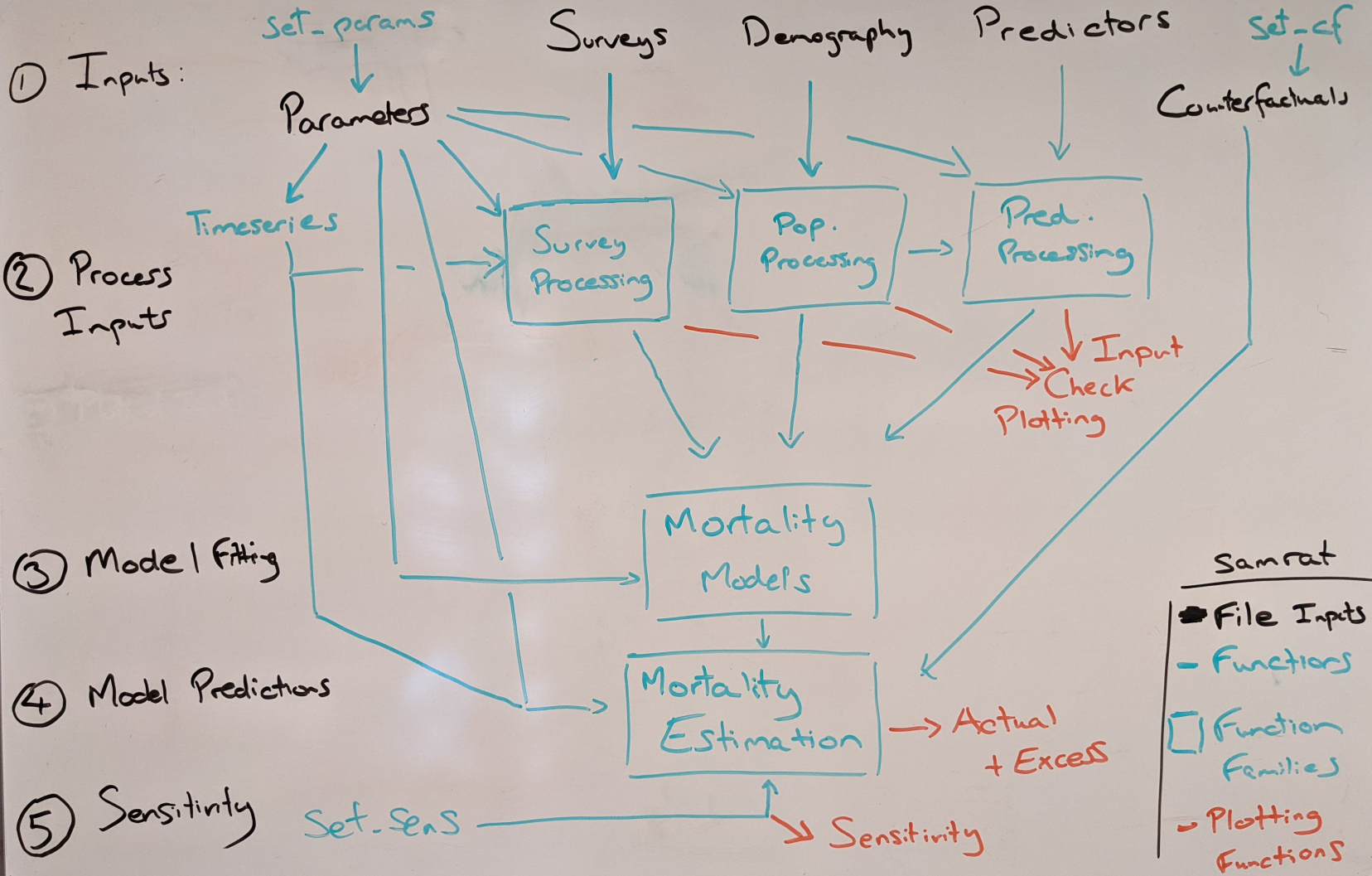
Samrat Structure
Directory concepts
For each analysis, we will try to keep to a one directory per analysis structure, which will include:
- Input parameter files (xlsx, csv, rds)
- Survey dataset directory
In this directory, the output of analysis will be stored in
output.
This setup can then be linked with suitable reproducibility pipelines later on (cf orderly).
Conversion from mortality_small_area_estimation repo
In the originating
repository the use of global variables was quite extensive and made
tracking where variables originated from hard, with many variables being
assigned using get and assign calls by
reference to data.frames that listed the names of the
variables. This made it quite hard to identify where the variable
originated from and when errors appear make debugging almost impossible.
In response, we choose to create names lists of variables
and data sources. These are bundled within a list, in which
the data.frames used to create these named
lists are also included with the same name as in the
original repo.
For example, previously we had a predictors xlsx file. This had a
predictors_table sheet that described each of the data sets
that were being imported from the other sheets as well as a dictionary
sheet with more information. From this, the
predictors_table sheet would be read in as
predictors in the form of a data.frame. From
this the actual predictor data sets would be read in and assigned to
variable names determined from predictors.
Instead, we now opt for the predictors
data.frame and the dictionary
data.frame to be named list elements within
predictors_list - this is a list object that also has a
predictors_list named element that is a named
list of data.frames for the actual predictor
data sets. This way when referring to these, we know where they came
from.